



How Transparent Are Foundation Model Developers?
Introducing the Foundation Model Transparency Index

Foundation models such as GPT-4 and Stable Diffusion 2 are the engines of generative AI. While the societal impact of foundation models is growing, transparency is on the decline, mirroring the opacity that has plagued past digital technologies like social media. How are these models trained and deployed? Once released, how do users actually use them? Who are the workers that build the datasets that these systems rely on, and how much are they paid? Transparency about these questions is important to keep companies accountable and understand the societal impact of foundation models.
Today, we're introducing the Foundation Model Transparency Index to aggregate transparency information from foundation model developers, identify areas for improvement, push for change, and track progress over time. This effort is a collaboration between researchers from Stanford, MIT, and Princeton.
The inaugural 2023 version of the index consists of 100 indicators that assess the transparency of the developers' practices around developing and deploying foundation models. Foundation models impact societal outcomes at various levels, and we take a broad view of what constitutes transparency.
Our indicators include the social aspects of training foundation models (the impact on labor, environment, and the usage policy for real-world use) in addition to technical aspects (data, compute, and details about the model training process). For example, we assess whether developers disclose the wages for workers who performed the data labor, the computational resources used for developing the models, and how they enforce their usage policy.
The indicators are based on, and synthesize, past interventions aimed at improving the transparency of AI systems, such as model cards, datasheets, evaluation practices, and how foundation models intermediate a broader supply chain.
Read the paper here.
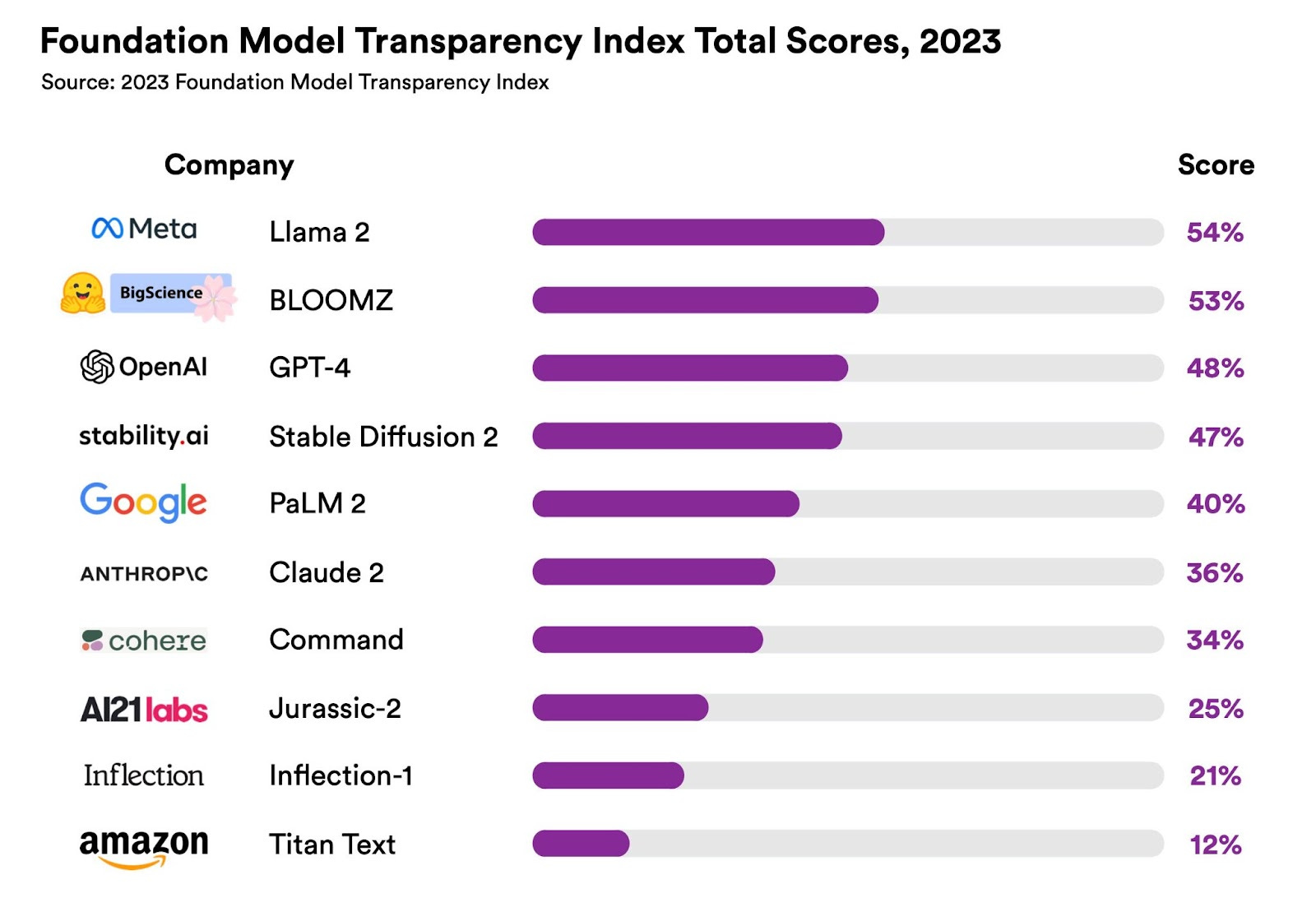
We assess 10 major foundation model developers and their flagship models on the index’s 100 indicators, and find areas for significant improvement across the board. The average score is just 37 out of 100, with even the highest-scoring developers barely eclipsing 50. Yet, 82 of the indicators are satisfied by at least one developer, showing that improvement is already possible if developers implement practices already in place by their competitors. After scoring developers, we reached out to them for their response and rebuttals. All 10 developers responded to our work, and 8 contested their scores. The figure above represents the final scores for each developer after resolving developers’ rebuttals.

We also dissected the concept of transparency to provide a clearer picture of where developers are transparent. Transparency is poor on matters related to how models are built. In particular, developers are opaque on what data is used to train their model, who provides that data and how much they are paid, and how much computation is used to train the model. Developers likewise score poorly on transparency of the downstream impact of their models, since they disclose next-to-nothing about how their models are used in the real world.
Three developers in our list (Meta, Hugging Face, and Stability AI) develop open foundation models (Llama 2, BLOOMZ, and Stable Diffusion 2 respectively): the model weights can be downloaded. The other seven developers built closed foundation models—the model weights aren't publicly downloadable, and the model has to be accessed via an API.
Developers of open foundation models scored higher in many axes of transparency, despite many of our indicators being easier to satisfy for closed models. For example, many indicators assessed policies for downstream use. Since closed model developers often provide access only through an API, they can share information related to downstream use more easily, whereas developers of open models need to collaborate with the downstream deployers to satisfactorily provide such information. In theory, this should mean a much higher score for closed models on these indicators, but we find no substantive difference. Still, some closed developers indeed perform better on these indicators, with OpenAI leading the way.
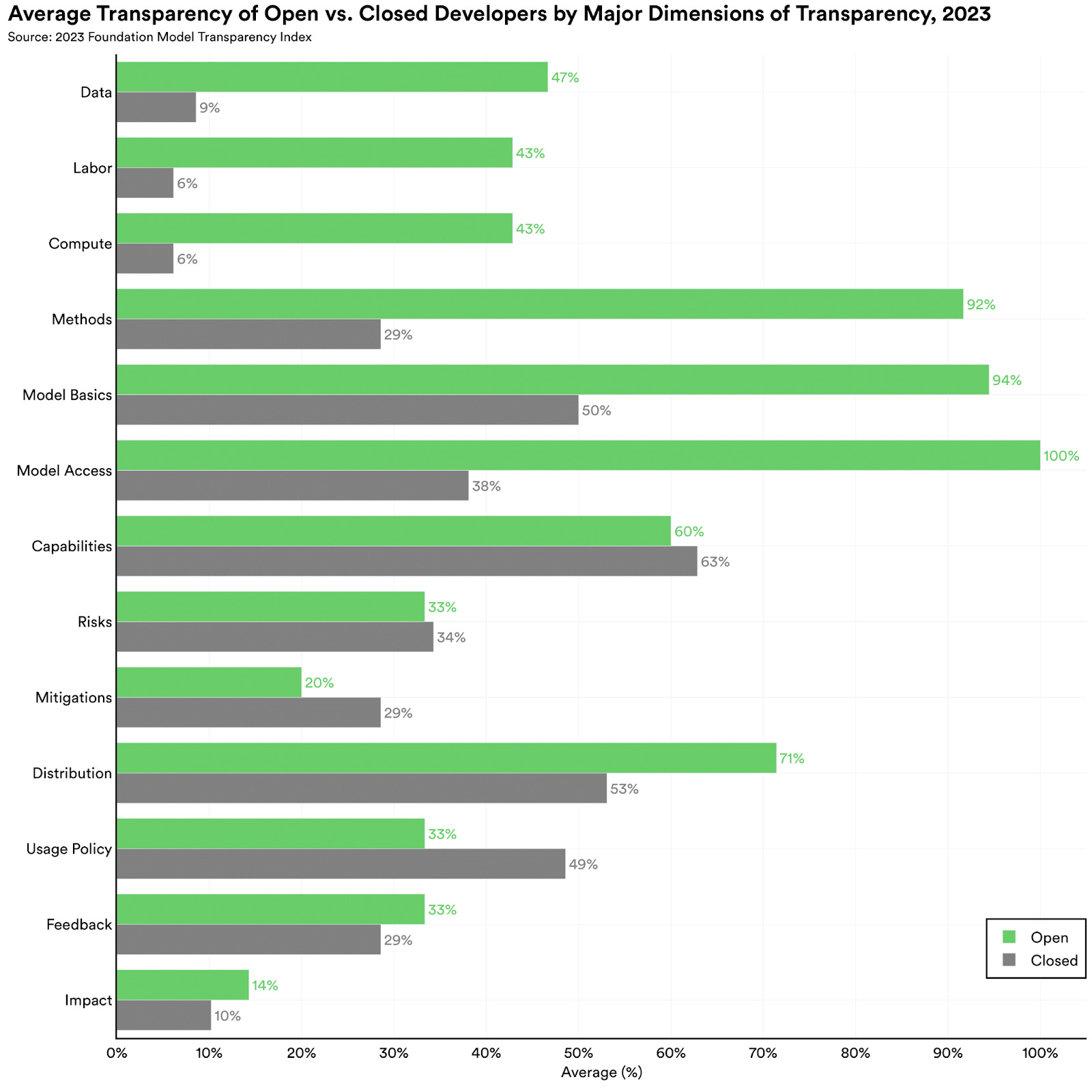
In terms of overall scores, open foundation model developers lead the way. The difference between developers of open and closed models is especially pronounced for indicators about the resources required to build models, such as data and compute. In recent years, many developers of closed models have become increasingly secretive about the methodology for training their models.
For a more in-depth analysis of our methods and findings, see the paper. The authors are Rishi Bommasani, Kevin Klyman, Shayne Longpre, Sayash Kapoor, Nestor Maslej, Betty Xiong, Daniel Zhang, and Percy Liang.
In addition, we release a rich repository with all of our analysis, including precise definitions of each indicator, the raw data with our scores for each developer, and a justification for each score, on our GitHub repository. We hope that this data is useful for further analyses of the budding foundation model ecosystem.
This is really cool, great step forward! How are the individual measures weighted to form the final score?
Thanks, guys!!! This is amazing!!! How are we to think about the fact that the highest percentage here is 54%? If these models were taking one of my classes, none would be passing at this point? What would it take for a model to raise its percentile to a more acceptable level?