



Could AI slow science?
Confronting the production-progress paradox


AI leaders have predicted that it will enable dramatic scientific progress: curing cancer, doubling the human lifespan, colonizing space, and achieving a century of progress in the next decade. Given the cuts to federal funding for science in the U.S., the timing seems perfect, as AI could replace the need for a large scientific workforce.
It’s a common-sense view, at least among technologists, that AI will speed science greatly as it gets adopted in every part of the scientific pipeline — summarizing existing literature, generating new ideas, performing data analyses and experiments to test them, writing up findings, and performing “peer” review.
But many early common-sense predictions about the impact of a new technology on an existing institution proved badly wrong. The Catholic Church welcomed the printing press as a way of solidifying its authority by printing Bibles. The early days of social media led to wide-eyed optimism about the spread of democracy worldwide following the Arab Spring.
Similarly, the impact of AI on science could be counterintuitive. Even if individual scientists benefit from adopting AI, it doesn’t mean science as a whole will benefit. When thinking about the macro effects, we are dealing with a complex system with emergent properties. That system behaves in surprising ways because it is not a market. It is better than markets at some things, like rewarding truth, but worse at others, such as reacting to technological shocks. So far, on balance, AI has been an unhealthy shock to science, stretching many of its processes to the breaking point.
Any serious attempt to forecast the impact of AI on science must confront the production-progress paradox. The rate of publication of scientific papers has been growing exponentially, increasing 500 fold between 1900 and 2015. But actual progress, by any available measure, has been constant or even slowing. So we must ask how AI is impacting, and will impact, the factors that have led to this disconnect.
Our analysis in this essay suggests that AI is likely to worsen the gap. This may not be true in all scientific fields, and it is certainly not a foregone conclusion. By carefully and urgently taking actions such as those we suggest below, it may be possible to reverse course. Unfortunately, AI companies, science funders, and policy makers all seem oblivious to what the actual bottlenecks to scientific progress are. They are simply trying to accelerate production, which is like adding lanes to a highway when the slowdown is actually caused by a toll booth. It’s sure to make things worse.
Table of contents
1. Science has been slowing — the production-progress paradox
2. Why is progress slowing? Can AI help?
3. Science is not ready for software, let alone AI
4. AI might prolong the reliance on flawed theories
5. Human understanding remains essential
6. Implications for the future of science
Science has been slowing — the production-progress paradox
The total number of published papers is increasing exponentially, doubling every 12 years. The total number of researchers who have authored a research paper is increasing even more quickly. And between 2000 and 2021, investment in research and development increased fourfold across the top seven funders (the US, China, Japan, Germany, South Korea, the UK, and France).1
But does this mean faster progress? Not necessarily. Some papers lead to fundamental breakthroughs that change the trajectory of science, while others make minor improvements to known results.
Genuine progress results from breakthroughs in our understanding. For example, we understood plate tectonics in the middle of the last century — the idea that the continents move. Before that, geologists weren’t even able to ask the right questions. They tried to figure out the effects of the cooling of the Earth, believing that that’s what led to geological features such as mountains. No amount of findings or papers in older paradigms of geology would have led to the same progress that plate tectonics did.
So it is possible that the number of papers is increasing exponentially while progress is not increasing at the same rate, or is even slowing down. How can we tell if this is the case?
One challenge in answering this question is that, unlike the production of research, progress does not have clear, objective metrics. Fortunately, an entire research field — the "science of science", or metascience — is trying to answer this question. Metascience uses the scientific method to study scientific research. It tackles questions like: How often can studies be replicated? What influences the quality of a researcher's work? How do incentives in academia affect scientific outcomes? How do different funding models for science affect progress? And how quickly is progress really happening?
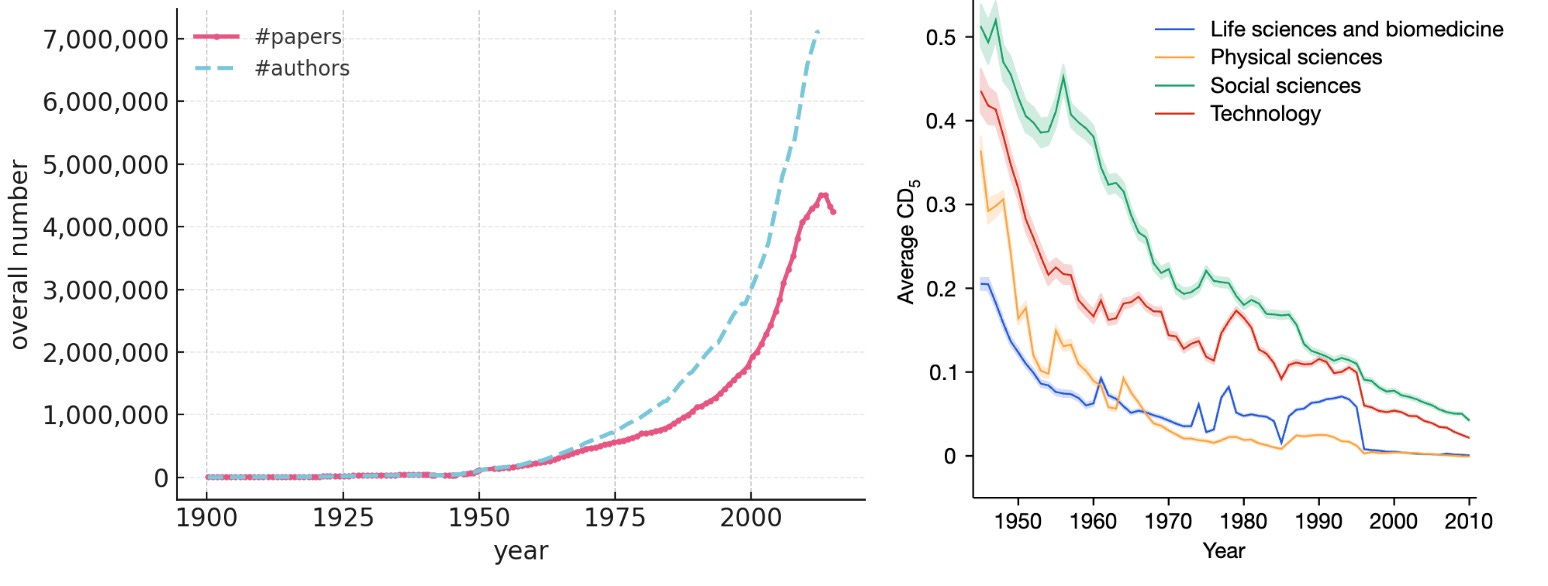
Strikingly, many findings from metascience suggest that progress has been slowing down, despite dramatic increases in funding, the number of papers published, and the number of people who author scientific papers. We collect some evidence below; Matt Clancy reviews many of these findings in much more depth.
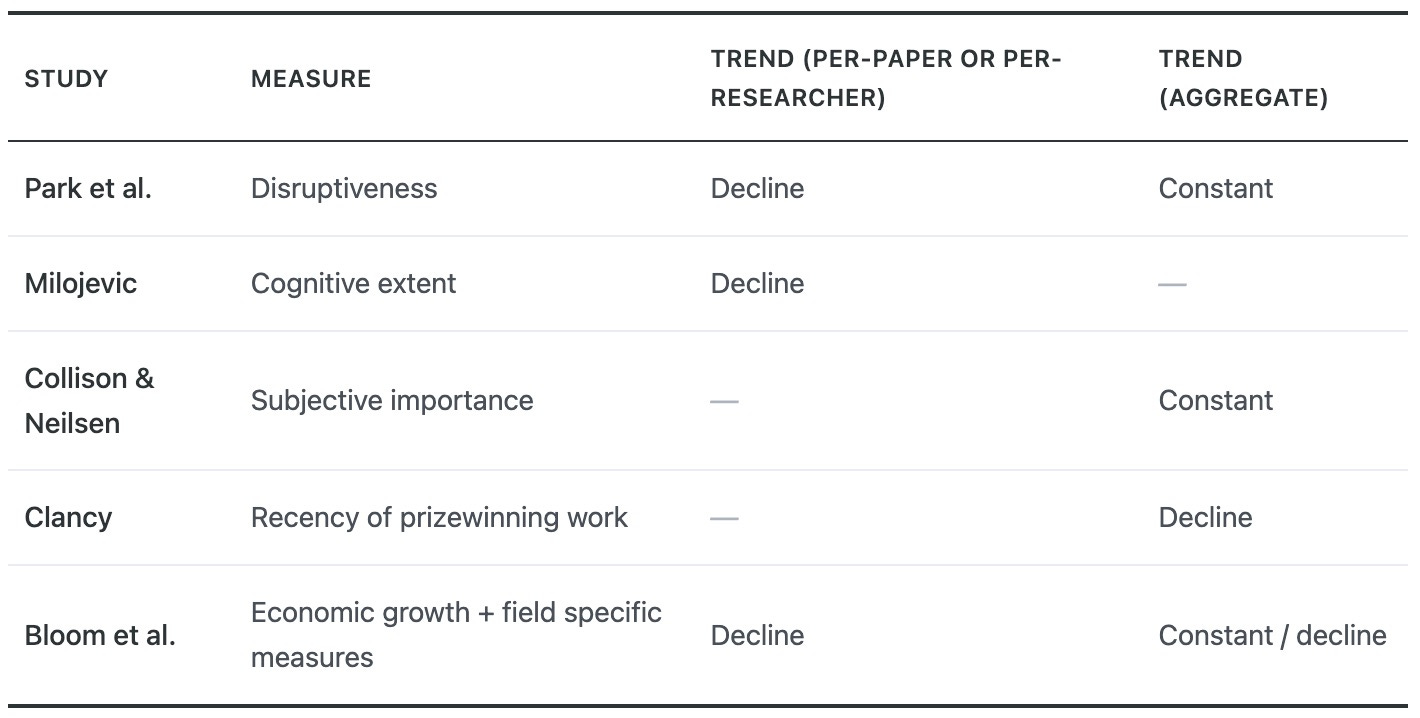
1) Park et al. find that "disruptive" scientific work represents an ever-smaller fraction of total scientific output. Despite an exponential increase in the number of published papers and patents, the number of breakthroughs is roughly constant.
2) Research that introduces new ideas is more likely to coin new terms. Milojevic collects the number of unique phrases used in titles of scientific papers over time as a measure of the “cognitive extent” of science, and finds that while this metric increased up until the early 2000s, it has since entered a period of stagnation, when the number of unique phrases used in titles of research papers has gone down.
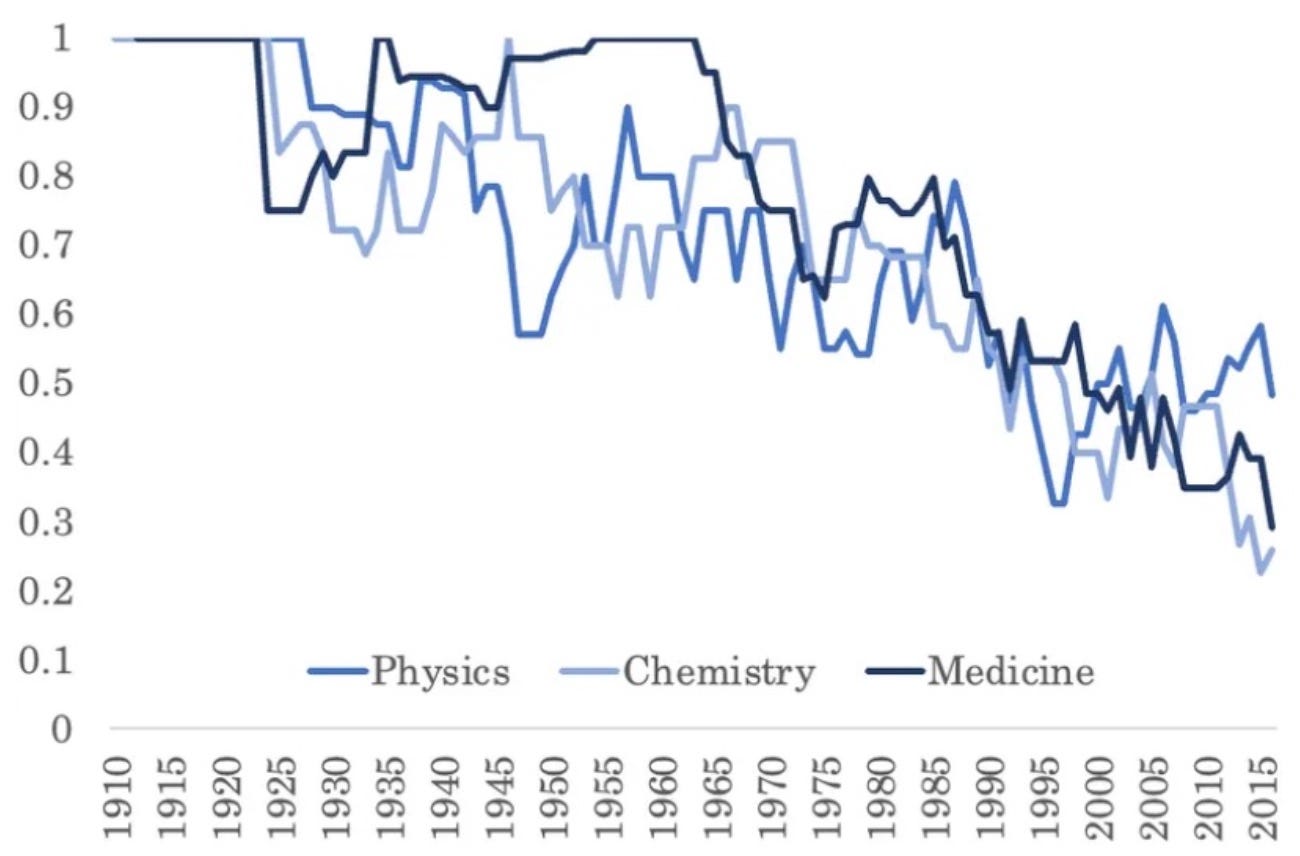
3) Patrick Collison and Michael Nielsen surveyed researchers across fields on how they perceived progress in the most important breakthroughs in their fields over time — those that won a Nobel prize. They asked scientists to compare Nobel-prize-winning research from the 1910s to the 1980s.
They found that scientists considered advances from earlier decades to be roughly as important as the ones from more recent decades, across Medicine, Physics, and Chemistry. Despite the vast increases in funding, published papers, and authors, the most important breakthroughs today are about as impressive as those in the decades past.
4) Matt Clancy complements this with an analysis of what fraction of discoveries that won a Nobel Prize in a given year were published in the preceding 20 years. He found that this number dropped from 90% in 1970 to 50% in 2015, suggesting that either transformative discoveries are happening at a slower pace, or that it takes longer for discoveries to be recognized as transformative.
5) Bloom et al. analyze research output from an economic perspective. Assuming that economic growth ultimately comes from new ideas, the constant or declining rate of growth implies that the exponential increase in the number of researchers is being offset by a corresponding decline in the output per researcher. They find that this pattern holds true when drilling down into specific areas, including semiconductors, agriculture, and medicine (where the progress measures are Moore’s law, crop yield growth, and life expectancy, respectively).

Of course, there are shortcomings in each of the metrics above. This is to be expected: since progress doesn't have an objective metric, we need to rely on proxies for measuring it, and these proxies will inevitably have some flaws.
For example, Park et al. used citation patterns to flag papers as "disruptive": if follow-on citations to a given paper don't also cite the studies this paper cited, the paper is more likely to be considered disruptive. One criticism of the paper is that this could simply be a result of how citation practices have evolved over time, not a result of whether a paper is truly disruptive. And the metric does flag some breakthroughs as non-disruptive — for example, AlphaFold is not considered a disruptive paper by this metric.2
But taken together, the findings do suggest that scientific progress is slowing down, at least compared to the volume of papers, researchers, and resources. Still, this is an area where further research would be fruitful — while the decline in the pace of progress relative to inputs seems very clear, it is less clear what is happening at an aggregate level. Furthermore, there are many notions of what the goals of science are and what progress even means, and it is not clear how to connect the available progress measures to these higher-level definitions.
Why is progress slowing? Can AI help?
There are many hypotheses for why progress could be slowing. One set of hypotheses is that slowdown is an intrinsic feature of scientific progress, and is what we should expect. For example, there’s the low-hanging fruit hypothesis — the easy scientific questions have already been answered, so what remains to be discovered is getting harder.
This is an intuitively appealing idea. But we don’t find this convincing. Adam Mastroianni gives many compelling counter-arguments. He points out that we’ve been wrong about this over and over and lists many comically mis-timed assessments of scientific fields reaching saturation just before they ended up undergoing revolutions, such as physics in the 1890s.
While it’s true that lower-hanging fruits get picked first, there are countervailing factors. Over time, our scientific tools improve and we stand on the tower of past knowledge, making it easier to reach higher. Often, the benefits of improved tools and understanding are so transformative that whole new fields and subfields are created. New fields from the last 50-100 years include computer science, climate science, cognitive neuroscience, network science, genetics, molecular biology, and many others. Effectively, we’re plucking fruit from new trees, so there is always low-hanging fruit.
In our view, the low-hanging fruit hypothesis can at best partly explain slowdowns within fields. So it’s worth considering other ideas.
The second set of hypotheses is less fatalistic. They say that there’s something suboptimal about the way we’ve structured the practice of science, and so the efficiency of converting scientific inputs into progress is dropping. In particular, one subset of hypotheses flags the increase in the rate of production itself as the causal culprit — science is slowing down because it is trying to go too fast.
How could this be? The key is that any one scientist’s attention is finite, so they can only pay attention to a limited number of papers every year. So it is too risky for authors of papers to depart from the canon. Any such would-be breakthrough papers would be lost in the noise and won’t get the attention of a critical mass of scholars. The greater the rate of production, the more the noise, so the less attention truly novel papers will achieve, and thus will be less likely to break through into the canon.
Chu and Evans explain:
when the number of papers published each year grows very large, the rapid flow of new papers can force scholarly attention to already well-cited papers and limit attention for less-established papers—even those with novel, useful, and potentially transformative ideas. Rather than causing faster turnover of field paradigms, a deluge of new publications entrenches top-cited papers, precluding new work from rising into the most-cited, commonly known canon of the field.
These arguments, supported by our empirical analysis, suggest that the scientific enterprise’s focus on quantity may obstruct fundamental progress. This detrimental effect will intensify as the annual mass of publications in each field continues to grow
Another causal mechanism relates to scientists’ publish-or-perish incentives. Production is easy to measure, and progress is hard to measure. So universities and other scientific institutions judge researchers based on measurable criteria such as how many papers they publish and the amount of grant funding they receive. It is not uncommon for scientists to have to publish a certain number of peer-reviewed papers to be hired or to get tenure (either due to implicit norms or explicit requirements).
The emphasis on production metrics seems to be worsening over time. Physics Nobel winner Peter Higgs famously noted that he wouldn't even have been able to get a job in modern academia because he wouldn't be considered productive enough.
So individual researchers' careers might be better off if they are risk averse, but it might reduce the collective rate of progress. Rzhetsky et al. find evidence of this phenomenon in biomedicine, where experiments tend to focus too much on experimenting with known molecules that are already considered important (which would be more likely to lead to publishing a paper) rather than more risky experiments that could lead to genuine breakthroughs. Worryingly, they find this phenomenon worsening over time.
This completes the feedback loop: career incentives lead to researchers publishing more papers, and disincentivize novel research that results in true breakthroughs (but might only result in a single paper after years of work).
If slower progress is indeed being caused by faster production, how will AI impact it? Most obviously, automating parts of the scientific process will make it even easier for scientists to chase meaningless productivity metrics. AI could make individual researchers more creative but decrease the creativity of the collective because of a homogenizing effect. AI could also exacerbate the inequality of attention and make it even harder for new ideas to break through. Existing search technology, such as Google Scholar, seems to be having exactly this effect.
To recap, so far we’ve argued that if the slowdown in science is caused by overproduction, AI will make it worse. In the next few sections, we’ll discuss why AI could worsen the slowdown regardless of what’s causing it.
Science is not ready for software, let alone AI
How do researchers use AI? In many ways: AI-based modeling to uncover trends in data using sophisticated pattern-matching algorithms; hand-written machine learning models specified based on expert knowledge; or even generative AI to write the code that researchers previously wrote. While some applications, such as using AI for literature review, don't involve writing code, most applications of AI for science are, in essence, software development.
Unfortunately, scientists are notoriously poor software engineers. Practices that are bog-standard in the industry, like automated testing, version control, and following programming design guidelines, are largely absent or haphazardly adopted in the research community. These are practices that were developed and standardized over the last six decades of software engineering to prevent bugs and ensure the software works as expected.
Worse, there is little scrutiny of the software used in scientific studies. While peer review is a long and arduous step in publishing a scientific paper, it does not involve reviewing the code accompanying the paper, even though most of the "science" in computational research is being carried out in the code and data accompanying a paper, and only summarized in the paper itself.
In fact, papers often fail to even share the code and data used to generate results, so even if other researchers are willing to review the code, they don't have the means to. Gabelica et al. found that of 1,800 biomedical papers that pledged to share their data and code, 93% did not end up sharing these artifacts. This even affects results in the most prominent scientific journals: Stodden et al. contacted the authors of 204 papers published in Science, one of the top scientific journals, to get the code and data for their study. Only 44% responded.
When researchers do share the code and data they used, it is often disastrously wrong. Even simple tools, like Excel, have notoriously led to widespread errors in various fields. A 2016 study found that one in five genetics papers suffer from Excel-related errors, for example, because the names of genes (say, Septin 2) were automatically converted to dates (September 2). Similarly, it took decades for most scientific communities to learn how to use simple statistics responsibly.
AI opens a whole new can of worms. The AI community often advertises AI as a silver bullet without realizing how difficult it is to detect subtle errors. Unfortunately, it takes much less competence to use AI tools than to understand them deeply and learn to identify errors. Like other software-based research, errors in AI-based science can take a long time to uncover. If the widespread adoption of AI leads to researchers spending more time and effort conducting or building on erroneous research, it could slow progress, since researcher time and effort are wasted in unproductive research directions.
Unfortunately, we've found that AI has already led to widespread errors. Even before generative AI, traditional machine learning led to errors in over 600 papers across 30 scientific fields. In many cases, the affected papers constituted the majority of the surveyed papers, raising the possibility that in many fields, the majority of AI-enabled research is flawed. Others have found that AI tools are often used with inappropriate baseline comparisons, making it incorrectly seem like they outperform older methods. These errors are not just theoretical: they affect the potential real-world deployment of AI too. For example, Roberts et al. found that of 400+ papers using AI for COVID-19 diagnosis, none produced clinically useful tools due to methodological flaws.
Applications of generative AI can result in new types of errors. For example, while AI can aid in programming, code generated using AI often has errors. As AI adoption increases, we will discover more applications of AI for science. We suspect we'll find widespread errors in many of these applications.
Why is the scientific community so far behind software engineering best practices? In engineering applications, bugs are readily visible through tests, or in the worst case, when they are deployed to customers. Companies have strong incentives to fix errors to maintain the quality of their applications, or else they will lose market share. As a result, there is a strong demand for software engineers with deep expertise in writing good software (and now, in using AI well). This is why software engineering practices in the industry are decades ahead of those in research. In contrast, there are few incentives to correct flawed scientific results, and errors often persist for years.
That is not to say science should switch from a norms-based to a market-based model. But it shouldn't be surprising that there are many problems markets have solved that science hasn't — such as developing training pipelines for software engineers. Where such gaps between science and the industry emerge, scientific institutions need to intentionally adopt industry best practices to ensure science continues to innovate, without losing what makes science special.
In short, science needs to catch up to a half century of software engineering — fast. Otherwise, its embrace of AI will lead to an avalanche of errors and create headwinds, not tailwinds for progress.
AI could help too. There are many applications of AI to spot errors. For example, the Black Spatula project and the YesNoError project use AI to uncover flaws in research papers. In our own work, we've developed benchmarks aiming to spur the development of AI agents that automatically reproduce papers. Given the utility of generative AI for writing code, AI itself could be used to improve researchers' software engineering practices, such as by providing feedback, suggestions, best practices, and code reviews at scale. If such tools become reliable and see widespread adoption, AI could be part of the solution by helping avoid wasted time and effort building on erroneous work. But all of these possibilities require interventions from journals, institutions, and funding agencies to incentivize training, synthesis, and error detection rather than production alone.
AI might prolong the reliance on flawed theories
One of the main uses of AI for science is modeling. Older modeling techniques required coming up with a hypothesis for how the world works, then using statistical models to make inferences about this hypothesis.
In contrast, AI-based modeling treats this process as a black box. Instead of making a hypothesis about the world and improving our understanding based on the model's results, it simply tries to improve our ability to predict what outcomes would occur based on past data.
Leo Breiman illustrated the differences between these two modeling approaches in his landmark paper "Statistical Modeling: The Two Cultures". He strongly advocated for AI-based modeling, often on the basis of his experience in the industry. A focus on predictive accuracy is no doubt helpful in the industry. But it could hinder progress in science, where understanding is crucial.
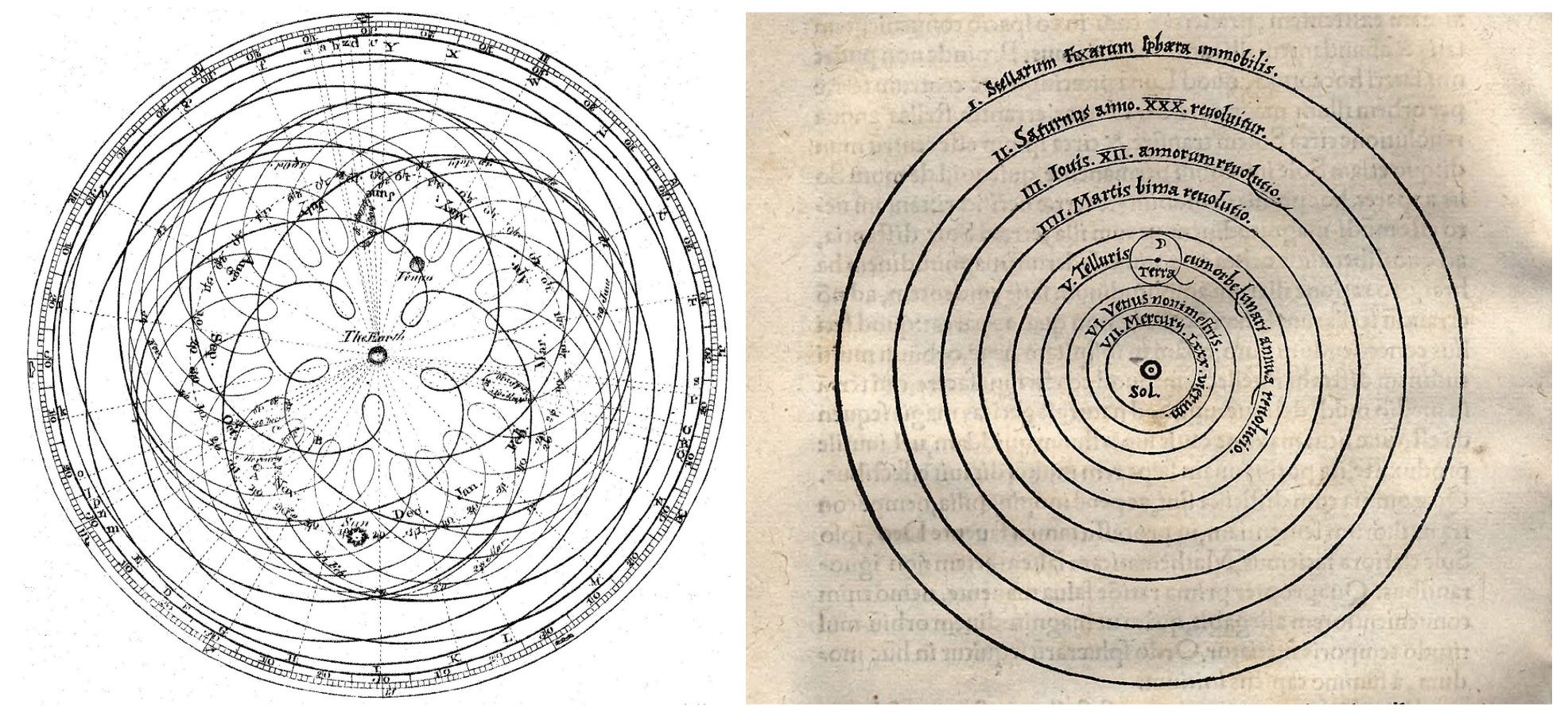
Why? In a recent commentary in the journal Nature, we illustrated this with an analogy to the geocentric model of the Universe in astronomy. The geocentric model of the Universe—the model of the Universe with the Earth at the center—was very accurate at predicting the motion of planets. Workarounds like "epicycles" made these predictions accurate. (Epicycles were the small circles added to the planet's trajectory around the Earth).
Whenever a discrepancy between the model's predictions and the experimental readings was observed, astronomers added an epicycle to improve the model's accuracy. The geocentric model was so accurate at predicting planets' motions that many modern planetariums still use it to compute planets' trajectories.
{kind=link}
{kind=link}
How was the geocentric model of the Universe overturned in favor of the heliocentric model — the model with the planets revolving around the Sun? It couldn't be resolved by comparing the accuracy of the two models, since the accuracy of the models was similar. Rather, it was because the heliocentric model offered a far simpler explanation for the motion of planets. In other words, advancing from geocentrism to heliocentrism required a theoretical advance, rather than simply relying on the more accurate model.
This example shows that scientific progress depends on advances in theory. No amount of improvements in predictive accuracy could get us to the heliocentric model of the world without updating the theory of how planets move.
Let's come back to AI for science. AI-based modeling is no doubt helpful in improving predictive accuracy. But it doesn't lend itself to an improved understanding of these phenomena. AI might be fantastic at producing the equivalents of epicycles across fields, leading to the prediction-explanation fallacy.
In other words, if AI allows us to make better predictions from incorrect theories, it might slow down scientific progress if this results in researchers using flawed theories for longer. In the extreme case, fields would be stuck in an intellectual rut even as they excel at improving predictive accuracy within existing paradigms.
Could advances in AI help overcome this limitation? Maybe, but not without radical changes to modeling approaches and technology, and there is little incentive for the AI industry to innovate on this front. So far, improvements in predictive accuracy have greatly outpaced improvements in the ability to model the underlying phenomena accurately.

Human understanding remains essential
In solving scientific problems, scientists build up an understanding of the phenomena they study. It might seem like this understanding is just a way to get to the solution. So if we can automate the process of going from problem to solution, we don’t need the intermediate step.
The reality is closer to the opposite. Solving problems and writing papers about them can be seen as a ritual that leads to the real prize, human understanding, without which there can be no scientific progress.
Fields Medal-winning mathematician William Thurston wrote an essay brilliantly illustrating this. At the outset, he emphasizes that the point of mathematics is not simply to figure out the truth value for mathematical facts, but rather the accompanying human understanding:
…what [mathematicians] are doing is finding ways for people to understand and think about mathematics.
The rapid advance of computers has helped dramatize this point, because computers and people are very different. For instance, when Appel and Haken completed a proof of the 4-color map theorem using a massive automatic computation, it evoked much controversy. I interpret the controversy as having little to do with doubt people had as to the veracity of the theorem or the correctness of the proof. Rather, it reflected a continuing desire for human understanding of a proof, in addition to knowledge that the theorem is true.
On a more everyday level, it is common for people first starting to grapple with computers to make large-scale computations of things they might have done on a smaller scale by hand. They might print out a table of the first 10,000 primes, only to find that their printout isn't something they really wanted after all. They discover by this kind of experience that what they really want is usually not some collection of "answers"—what they want is understanding. [emphasis in original]
He then describes his experience as a graduate student working on the theory of foliations, a center of attention among many mathematicians. After he proved a number of papers on the most important theorems in the field, counterintuitively, people began to leave the field:
I heard from a number of mathematicians that they were giving or receiving advice not to go into foliations—they were saying that Thurston was cleaning it out. People told me (not as a complaint, but as a compliment) that I was killing the field. Graduate students stopped studying foliations, and fairly soon, I turned to other interests as well.
I do not think that the evacuation occurred because the territory was intellectually exhausted—there were (and still are) many interesting questions that remain and that are probably approachable. Since those years, there have been interesting developments carried out by the few people who stayed in the field or who entered the field, and there have also been important developments in neighboring areas that I think would have been much accelerated had mathematicians continued to pursue foliation theory vigorously.
Today, I think there are few mathematicians who understand anything approaching the state of the art of foliations as it lived at that time, although there are some parts of the theory of foliations, including developments since that time, that are still thriving.
Two things led to this desertion. First, the results he documented were written in a way that was hard to understand. This discouraged newcomers from entering the field. Second, even though the point of mathematics is building up human understanding, the way mathematicians typically get credit for their work is by proving theorems. If the most prominent results in a field have already been proven, that leaves few incentives for others to understand a field's contributions, because they can't prove further results (which would ultimately lead to getting credit).
In other words, researchers are incentivized to prove theorems. More generally, researchers across fields are incentivized to find solutions to scientific problems. But this incentive only leads to progress because the process of proving theorems or finding solutions to problems also leads to building human understanding. As the desertion of work on foliations shows, when there is a mismatch between finding solutions to problems and building human understanding, it can result in slower progress.
This is precisely the effect AI might have: by solving open research problems without leading to the accompanying understanding, AI could erode these useful byproducts by reducing incentives to build understanding. If we use AI to short circuit this process of understanding, that is like using a forklift at the gym. You can lift heavier weights with it, sure, but that's not why you go to the gym.
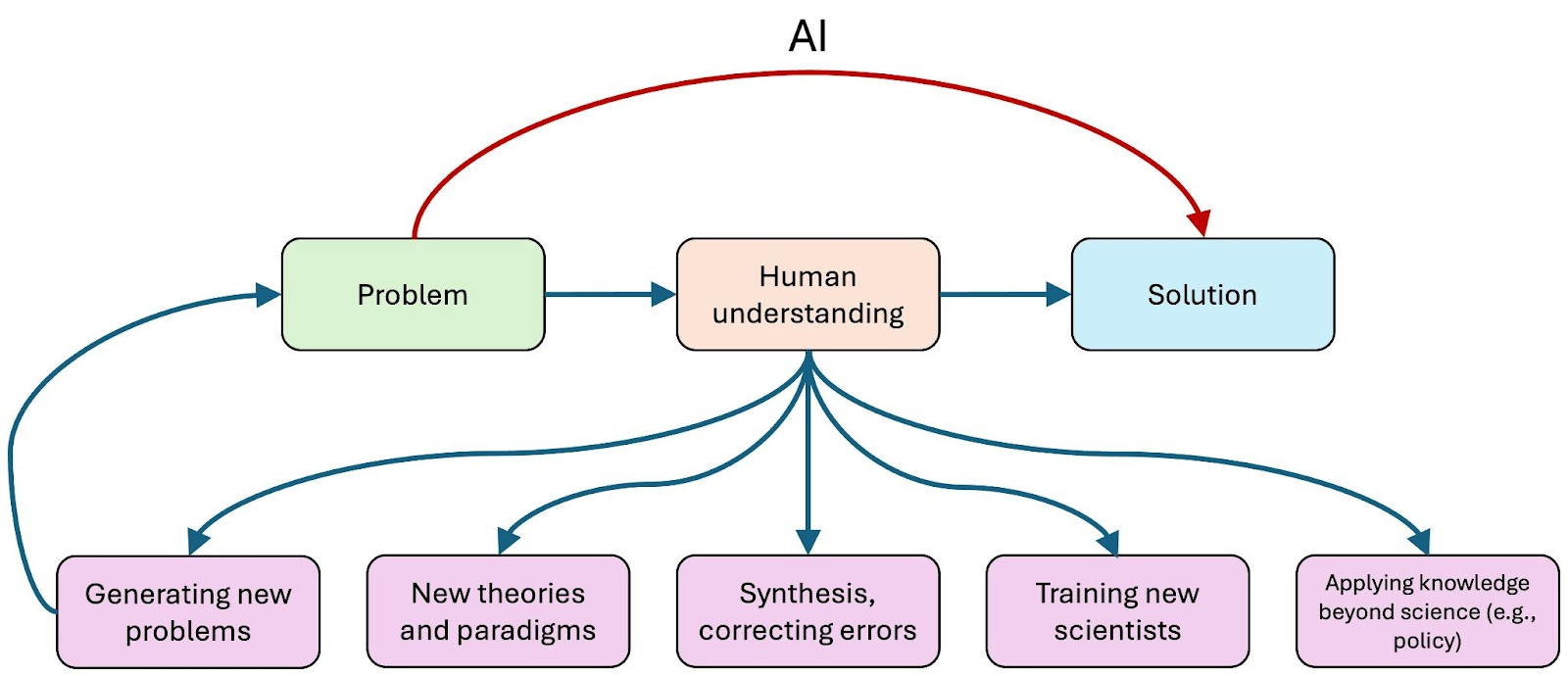
Of course, mathematics might be an extreme case, because human understanding is the end goal of (pure) mathematics, not simply knowing the truth value of mathematical statements. This might not be the case for many applications of science, where the end goal is to make progress towards a real-world outcome rather than human understanding, say, weather forecasting or materials synthesis.
Most fields lie in between these two extremes. If we use AI to bypass human understanding, or worse, retain only illusions of understanding, we might lose the ability to train new scientists, develop new theories and paradigms, synthesize and correct results, apply knowledge beyond science, or even generate new and interesting problems.
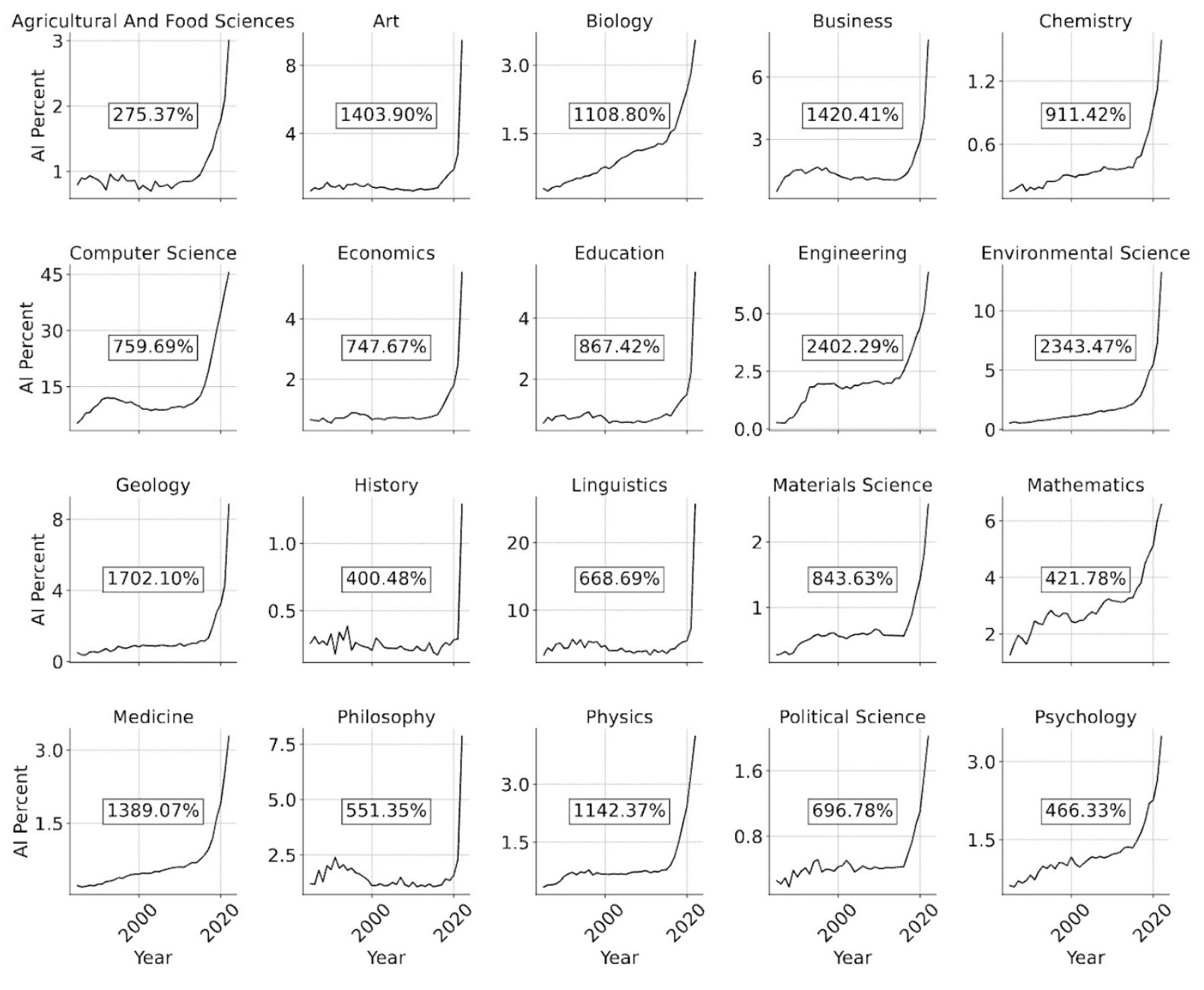
Empirical evidence across scientific fields has found evidence for some of these effects. For example, Hao et al. collect data from six fields and find that papers that adopt AI are more likely to focus on providing solutions to known problems and working within existing paradigms rather than generating new problems.
Of course, AI can also be used to build up tacit knowledge, such as by helping people understand mathematical proofs or other scientific knowledge. But this requires fundamental changes to how science is organized. Today's career incentives and social norms prize solutions to scientific problems over human understanding. As AI adoption accelerates, we need changes to incentives to make sure human understanding is prioritized.
Implications for the future of science
Over the last decade, scientists have been in a headlong rush to adopt AI. The speed has come at the expense of any ability to adapt slow-moving scientific institutional norms to maintain quality control and identify and preserve what is essentially human about science. As a result, the trend is likely to worsen the production-progress paradox, accelerating paper publishing but only digging us deeper into the hole with regard to true scientific progress.
So, what should the scientific community do differently? Let’s talk about the role of individual researchers, funders, publishers and other gatekeepers, and AI companies.
Changing scientific practices
Individual researchers should be more careful when adopting AI. They should build software engineering skills, learn how to avoid a long and growing list of pitfalls in AI-based modeling, and ensure they don’t lose their expertise by using AI as a crutch or an oracle. Sloppy use of AI may help in the short run, but will hinder meaningful scientific achievement.
With all that said, we recognize that most individual researchers are rationally following their incentives (productivity metrics). Yelling at them is not going to help that much, because what we have are collective action problems. The actors with real power to effect change are journals, universities hiring & promotion committees, funders, policymakers, etc. Let’s turn to those next.
Investing in meta-science
Meta-science research has been extremely valuable in revealing the production-progress paradox. But so far, that finding doesn’t have a lot of analytical precision. There’s only the fuzzy idea that science is getting less bang for its buck. This finding is generally consistent with scientists’ vibes, and is backed by a bunch of different metrics that vaguely try to measure true progress. But we don’t have a clear understanding of what the construct (progress) even is, and we’re far from a consensus story about what’s driving the slowdown.
To be clear, we will never have One True Progress Metric. If we did, Goodhardt/Campbell’s law would kick in — “When a measure becomes a target, it ceases to be a good measure.” Scientists would start to furiously optimize it, just as we have done with publication and citation counts, and the gaming would render it useless as a way to track progress.
That said, there’s clearly a long way for meta-science to go in improving both our quantitative and (more importantly) our qualitative/causal understanding of progress and the slowdown. Meta-science must also work to understand the efficacy of solutions.
Despite recent growth, meta-science funding is a fraction of a percent of science funding (and research on the slowdown is only a fraction of that pie). If it is indeed true that science funding as a whole is getting orders of magnitude less bang for the buck than in the past, meta-science investment seems ruefully small.
Reforming incentives
Scientists constantly complain to each other about the publish-or-perish treadmill and are keenly aware that the production-focused reward structure isn’t great for incentivizing scientific progress. But efforts to change this have consistently failed. One reason is simple inertia. Then there’s the aforementioned Goodhart’s law — whatever new metric is instituted will quickly be gamed. A final difficulty is that true progress can only be identified retrospectively, on timescales that aren’t suitable for hiring and promotion decisions.
One silver lining is that as the cost of publishing papers further drops due to AI, it could force us to stop relying on production metrics. In the AI field itself, the effort required to write a paper is so low that we are heading towards a singularity, with some researchers being able to (co-)author close to 100 papers a year. (But, again, the perceived pace of actual progress seems mostly flat.) Other fields might start going the same route.
Thus, rewarding the publication of individual findings may simply not be an option for much longer. Instead, perhaps the kinds of papers that count toward career progress should be limited to things that are hard to automate, such as new theories or paradigms of scientific research. And such reforms to incentive structures should go hand-in-hand with shifts in funding.
One thing we don’t need is more incentives for AI adoption. As we explained above, it is already happening at breakneck speed, and is not the bottleneck.
Rethinking AI-for-science tools
When it comes to AI-for-science labs and scientific tools from big AI companies, the elephant in the room is that they are in it for the wrong reasons. They want flashy “AI discovers X!” headlines so that they can sustain the narrative that AI will solve humanity’s problems, which buys them favorable policy treatment. We are not holding our breath for this to change.
We should be skeptical of AI-for-science news headlines. Many of them are greatly exaggerated. The results may fail to reproduce, or AI may be framed as the main character when it was in fact one tool among many.
If there are any AI-for-science tool developers out there who actually want to help, here’s our advice. Target the actual bottlenecks instead of building yet another literature review tool. How about tools for finding errors in scientific code or other forms of quality control? Listen to the users. For example, mathematicians have repeatedly said that tools for improving human understanding are much more exciting than trying to automate theorem-proving, which they view as missing the point.
The way we evaluate AI-for-science tools should also change. Consider a literature review tool. There are three kinds of questions one can ask: Does it save a researcher time and produce results of comparable quality to existing tools? How does the use of the tool impact the researcher’s understanding of the literature compared to traditional search? What will the collective impacts on the community be if the tool were widely adopted — for example, will it further focus the community’s attention on already-famous papers? These three questions get at production, understanding, and progress respectively.
Currently, only the first question is considered part of what evaluation means. The latter two are out of scope, and there aren’t even established methods or metrics for such measurement. That means that AI-for-science evaluation is guaranteed to provide a highly incomplete and biased picture of the usefulness of these tools and minimize their potential harms.
Final thoughts
We ourselves are enthusiastic users of AI in our scientific workflows. On a day-to-day basis, it all feels very exciting. That makes it easy to forget that the impact of AI on science as an institution, rather than individual scientists, is a different question that demands a different kind of analysis. Writing this essay required fighting our own intuitions in many cases. If you are a scientist who is similarly excited about using these tools, we urge you to keep this difference in mind.
Our skepticism here has similarities and differences to our reasons for the slow timelines we laid out in AI as Normal Technology. In that paper, we explained that market mechanisms exert some degree of quality control, and many shoddy AI deployments have failed badly, forcing companies who care about their reputation to take it slow when deploying AI, especially for consequential tasks, regardless of how fast the pace of development is. But in science, adoption and quality control processes are decoupled, with the former being much faster.
We are optimistic that scientific norms and processes will catch up in the long run. But for now, it’s going to be a bumpy ride.
We are grateful to Eamon Duede for feedback on a draft of this essay.
Further reading
The American Science Acceleration Project (ASAP) is a national initiative with the stated goal of making American science "ten times faster by 2030". The offices of Senators Heinrich and Rounds recently requested feedback on how to achieve this. In our response, we emphasized the production-progress paradox, discussed why AI could slow (rather than hasten) scientific progress, and recommended policy interventions that could help.
Our colleague Alondra Nelson also wrote a response to the ASAP initiative, emphasizing that faster science is not automatically better, and highlighted many challenges that remain despite increasing the pace of production.
In a recent commentary in the journal Nature, we discussed why the proliferation of AI-driven modeling could be bad for science.
We have written about the use of AI for science in many previous essays in this newsletter:
Lisa Messeri and Molly Crockett offer a taxonomy of the uses of AI in science. They discuss many pitfalls of adopting AI in science, arguing we could end up producing more while understanding less.
Matt Clancy reviewed the evidence for slowdowns in science and innovation, and discussed interventions for incentivizing genuine progress.
The Institute for Progress released a podcast series on meta-science. Among other things, the series discusses concerns about slowdown and alternative models for funding and organizing science.
Update (July 17, 2025): Minor wording edits for clarity.
What will slow research isn’t AI. It’s the flood of preprints being treated like peer-reviewed work across AI and computer science. Right now, an undergrad with a Canva poster and a faculty sponsor can push out ten preprints in a semester and get them cited like they’ve reshaped the field. OSF allows researchers to delete preregistrations, which sounds harmless until it’s used to quietly erase bad or fraudulent work. If something gets flagged, it’s gone. No history, no accountability. That’s a perfect setup for bad actors.
And we still haven’t dealt with the reproducibility crisis. We didn’t fix it. We just buried it under buzzwords, hype, and career incentives. Simultaneously, we are using completely broken scientific metaphors to justify AI architectures. We’re still pretending spiking neurons are equivalent to RNNs. That synaptic noise is optimization. That the behavior of starving mice tells us how humans think. These comparisons aren’t science. They’re branding.
Research architectures are more expensive, more power-hungry, and more opaque than ever. Despite the lack of a clear path to profitability, AI continues to consume billions of dollars in funding. The hype keeps growing. Amplified work often prioritizes speed, clout, and marketability over real understanding.
AI isn't a threat to science. The hype is. The culture is around it. The people enabling it are.
This is a fantastic essay. I do think it is worth emphasizing (as you do point out) that there is a big difference between AI that outputs a solution and AI that outputs an explanation.
But as you point out, to favor explanation-producing-AI, the incentives need to be changed for that to become dominant. We should consider how this might be changed.
I also wrote something arguing explanation-producing and solution-producing AI are different in important ways: https://thomasddewitt.substack.com/p/the-new-ai-for-science-is-different